在基于LLM的众多应用中,检索增强生成(RAG)无疑是当前最受关注的技术。RAG最初设计是为了解决大型语言模型(LLM)面临的挑战,但很快人们发现它在解决企业的实际问题上尤为有效。事实上,许多企业并不关心是否使用了大型模型,他们更看重的是能否获得更高效的搜索能力。RAG正是提供了这样的解决方案,它不仅提高了搜索的准确性,还增强了生成内容的相关性。开源项目ChatPDF就是RAG技术应用的一个典型例子,它展示了RAG在实际应用中的潜力和价值。
什么是 RAG
为RAG铺垫了这么多,下面我们来看看什么是RAG
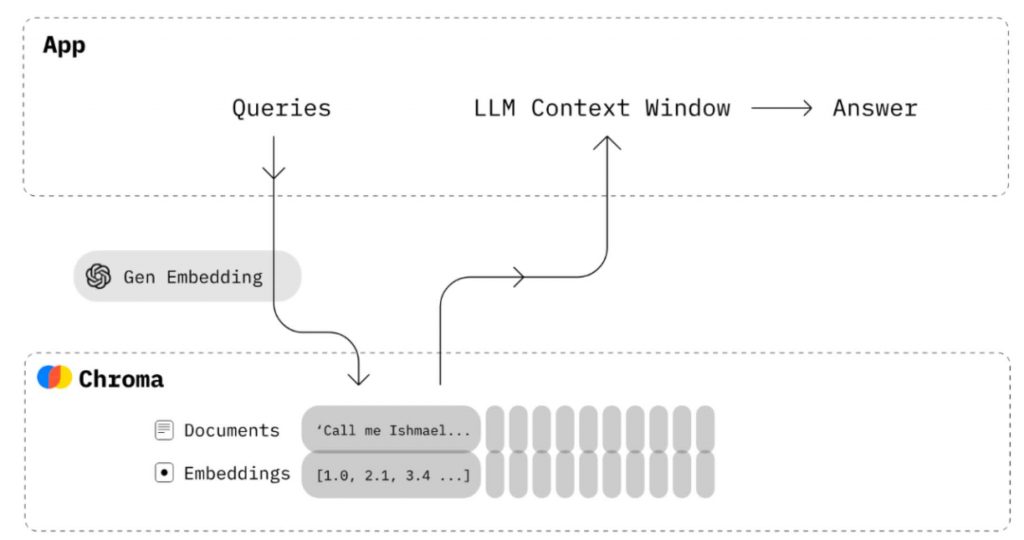
从开头的介绍里面大家已经可以看到,RAG——Retrieval Augmented Generation,检索增强生成。它的主要作用是生成(最终的答案),但是它先做了对现有文档的检索,而不是任由LLM来发挥。下面我提供一个浅显的例子来说明一下RAG:
假设一个工程师需要从厚厚的《业务操作手册》中找到相关的业务知识来帮助他完成工作,那么他有三种方式可以使用:
- 最原始:他可以去翻阅这么厚厚的《业务操作手册》,或者用去查询这么《业务操作手册》的电子版,然后认真阅读掌握操作方法。当然,如果他碰到的业务知识比较复杂,他就需要自己去综合这本书上面的多个章节的内容,并融会贯通;
- 借助问答机器人:他也可以直接去咨询问答机器人(chatbot),机器人也会把相应的知识吐给你。但是它可能有两个麻烦,一是它类似于FAQ,一问一答,还是需要自己去组合所有的回答内容;二是这个机器人需要前期大量的预训练知识库,需要专业的工程师去一条一条(其实是一个个知识条目,包括答案和多个相似问法),工作量极大,不太适合大面积推广使用;
- RAG:RAG的操作方式就是我们可以直接把这个《业务操作手册》的电子版上传到系统,系统在几分钟之内就可以把这篇“巨著”变成索引,供刚才那位工程师咨询。而且RAG给的答案会去综合正本手册的多个相关知识点,并用“专家”一样的口吻来给你答案:“要解决这个问题,你需要先解决两个前提,有三种方法来解决。下面我们一步步来看怎么做….”。
好了,我们现在知道RAG是个什么玩意儿了。你有没有发现,它其实会把之前的FAQ问答给取代掉。
RAG 系统构建挑战
在讨论 RAG 架构之前,我想分享一下最近关于构建 RAG 系统时常见故障点的研究【3】。研究人员分析了跨独特领域的三个案例研究,发现了七个常见的 RAG 故障点。
FP1 缺失的内容(Missing content)
在询问不能从现有文档中回答的问题时,在理想情况下,RAG 系统会以“抱歉,我不知道”之类的响应。然而,对于与内容相关但没有答案的问题,系统可能会被愚弄而给出响应。
FP2错过排名靠前的文档(Missed the top ranked documents)
问题的答案包含在文档中,但排名没有高到足以返回给用户。理论上,所有文档都会被排名并用于后续步骤。然而,在实践中,会返回前K个文档,其中K是一个根据性能选择的值。
FP3 未在上下文中 – 整合策略限制(Not in context – consolidation strategy limitations)
从数据库中检索包含答案的文档,当返回大量文档时,因为上下文的限制无法将其放入生成响应的上下文中,从而导致相关答案检索受到阻碍。
FP4 未提取(Not extracted)
当上下文中存在过多噪音或冲突信息时,虽然答案存在于上下文中,但模型无法提取正确的信息。
FP5 格式错误(Wrong format)
问题涉及提取特定格式的信息,如表格或列表等,但大型语言模型忽略了该指令。
FP6 错误特异性(Incorrect specificity)
返回的答案比较笼统或太具体,不可以满足用户的需求。
当RAG系统设计者希望为给定的教育问题提供具体的教育内容,而不仅仅是答案,但当用户不确定如何提问并且问题过于笼统时,就会出现错误的特异性。
FP7 不完整(Incomplete)
答案是准确的,但缺少一些信息,即使这些信息存在于上下文中并且可用于提取。 例如,提问“文件A、B、C中涵盖的要点是什么?”,答案就不太理想,而单独询问这些问题会更好。
如何构建企业 RAG 系统
现在我们已经确定了设计RAG系统时面临的常见问题,接下来让我们了解一下每个组件的设计需求,以及构建它们的最佳实践。
一、用户认证
系统中的第一个组件,在用户开始与聊天机器人交互之前,我们需要对用户进行身份验证。 身份验证有助于安全性和个性化,这对于企业系统来说是必须的。
1、访问控制
身份验证确保只有授权用户才能访问系统,有助于控制谁可以与系统交互以及允许他们执行哪些操作。
2、数据安全
保护敏感数据至关重要。 用户身份验证可防止未经授权的个人访问机密信息,从而防止数据泄露和未经授权的数据操纵。
3、用户隐私
身份验证可确保只有目标用户才能访问其个人信息和帐户详细信息,从而有助于维护用户隐私。 这对于与用户建立信任至关重要。
4、问责制
身份验证通过将系统内的操作与特定用户帐户绑定来确保责任。 这对于审核和跟踪用户活动至关重要,有助于识别和解决任何安全事件或可疑行为。
5、个性化和定制
身份验证允许系统识别单个用户,从而实现用户体验的个性化和定制化,包括定制的内容、偏好和设置。
二、输入保护
防止用户输入有害或包含私人信息至关重要, 最近研究表明,LLM越狱很容易,接下来让我们看看输入保护的不同场景。
1、匿名化
可以进行匿名化或编辑个人身份信息 ,例如姓名、地址或联系方式,有助于保护隐私并防止恶意企图泄露敏感信息。
2、限制子字符串
禁止可用于 SQL 注入、跨站点脚本 (XSS) 或其他注入攻击的某些子字符串,防止安全漏洞或不良行为。
3、限制主题
限制不适当、冒犯或违反社区准则的特定主题相关的讨论或输入,过滤掉涉及仇恨、辱骂、歧视或露骨内容。
4、限制代码
防止注入可能危及系统安全或导致代码注入攻击的可执行代码。
5、限制语言
验证文本输入是否采用正确的语言或脚本,防止处理过程中潜在的误解或错误。
6、检测提示注入
减少注入误导性或有害提示的尝试,这些提示可能会以意想不到的方式操纵系统或影响LLM的行为。
7、限制tokens
对用户输入实施最大令牌或字符限制有助于避免资源耗尽并防止拒绝服务 (DoS) 攻击。
为了保护RAG 系统免受这些情况的影响,可以利用 Meta 的 Llama Guard。
三、数据索引
1、数据提取(Data ingestion)
- 文档解析:处理多种文档格式,例如 PDF、Word、Excel以及数据库和API等,识别和管理嵌入内容,例如超链接、多媒体元素或注释,以提供文档的全面表示。从不同文档格式中解析可能包含的图像和表格,因为从文档中的表格中识别和提取数据对于维护信息结构至关重要,尤其是在报告或研究论文中。 提取与表格相关的元数据,包括标题、行和列信息,可以增强对文档组织结构的理解,Table Transformer 等模型对于完成这项任务很有用。
- 数据处理:包括数据格式处理,不可识别内容的剔除,压缩和格式化等;
- 元数据提取:提取文件名、作者、创建日期、文档类型、关键字、章节title、图片alt等信息,非常关键,可将文档作为特殊字段进行索引。
2、分块(Chunking)
- 固定大小的分块方式:一般是256/512个tokens,取决于embedding模型的情况。但是这种方式的弊端是会损失很多语义,比如“我们今天晚上应该去吃个大餐庆祝一下”,很有可能就会被分在两个chunk里面——“我们今天晚上应该”、“去吃个大餐庆祝一下”。这样对于检索是非常不友好的,解决方法是增加冗余量,比如512tokens的,实际保存480tokens,一头一尾去保存相邻的chunk头尾的tokens内容;
- 特定格式分块:针对具有特定结构或语法特征的文本文件进行分块的一种方法,如 Markdown、LaTeX、Python 代码等。这种分块方式依据各自格式的特定字符或结构标记来实现,以保证分块后的内容在结构上的完整性和逻辑上的连贯性。比如 Markdown 文本可以使用标题(#)、列表(-)、引用(>)等来进行分块。
- 递归分块:以一组分隔符为参数,以递归的方式将文本分成更小的块。如果在第一次分割时无法得到所需长度的块,它将递归地继续尝试。每次递归都会尝试更细粒度的分割符号,直到块的长度满足要求。这样可以确保即使初始块很大,最终也能得到较为合适的小块。例如,可以先尝试按照句子结束符来分割(如句号或问号),如果这样分割出的文本块太长,就会依次尝试其他的标记,例如逗号或者空格。通过这种方式,我们可以找到比较合适的分割点,同时尽量避免破坏文本的语义结构。
- 语义分块(semantic chunking):首先在句子之间进行分割,句子通常是一个语义单位,它包含关于一个主题的单一想法;然后使用 Embedding 表征句子;最后将相似的句子组合在一起形成块,同时保持句子的顺序。
- 命题分块(propositional chunking):也是一种语义分块,它的原理是基于 LLM,逐步构建块。首先从基于段落的句法分块迭代开始。 对于每个段落,使用 LLM 生成独立的陈述(或者命题),比如我们可以使用简单的提示「这段文字讨论了哪些主题」。移除冗余命题。索引并存储生成的命题。在查询时,从命题语料库中检索,而不是原始文档语料库。
- 影响分块策略的因素:
- 取决于你的索引类型,包括文本类型和长度,文章和微博推文的分块方式就会很不同;
- 取决于你的模型类型:你使用什么LLM也会有不同,因为ChatGLM、ChatGPT和Claude.ai等的tokens限制长度不一样,会影响你分块的尺寸;
- 取决于问答的文本的长度和复杂度:最好问答的文本长度和你分块的尺寸差不多,这样会对检索效率更友好;
- 应用类型:你的RAG的应用是检索、问答和摘要等,都会对分块策略有不同的影响。
3、向量化(embedding)
这是将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解的格式,embedding模型的好坏会直接影响到后面检索的质量,特别是相关度。让我们探讨一下选择文本编码器的原因以及要考虑的因素。
- 利用 MTEB 基准进行评估:利用大规模文本嵌入基准 (MTEB)对编码器功能进行全面评估,该基准允许根据向量维度、平均检索性能和模型大小对编码器进行细致的评估。MTEB 不仅提供了对 OpenAI、Cohere 和 Voyager 等流行嵌入的性能的评估,还包括某些开源模型。
- 自定义评估:编码器可能无法始终如一地提供最佳性能,尤其是在处理敏感信息时。 在这种情况下,自定义评估方法至关重要。 以下是执行自定义评估的三种方法。1)通过注释评估:生成专用数据集并设置注释以获得黄金标签。 注释后,利用平均倒数排名 (MRR) 和标准化折扣累积增益 (NDCG) 等检索指标来定量评估不同编码器的性能;2)按模型评估:遵循与注释方法类似的数据生成过程,但使用 LLM 或交叉编码器作为评估器。 这允许在所有编码器之间建立相对排名。 随后,对前三个编码器的手动评估可以产生精确的性能指标;3)聚类评估:采用不同的聚类技术并分析不同 Silhouette 分数的覆盖范围(聚类的数据量),表明聚类内的向量相似性。 尝试 HDBSCAN 等算法,调整其参数以获得最佳性能选择。 这种基于聚类的评估提供了有关数据点的分布和分组的宝贵见解,有助于选择符合特定指标的编码器。
- 查询费用:OpenAI 和类似的提供商提供可靠的 API,消除了托管管理的需要。 然而,选择开源模型需要根据模型大小和延迟需求进行工程设计。 较小的模型(最多 110M 参数)可以使用 CPU 实例托管,而较大的模型可能需要 GPU 服务来满足延迟要求。
- 索引成本:选择高效的编码器服务,以降低因索引和查询共享编码器而产生的成本。建议将文档嵌入单独存储,以便在服务重置或迁移时,避免重新计算,减少成本。
- 仓储成本:对于大规模向量索引应用,需考虑存储成本与向量维度的线性关系。
- 搜索延迟:语义搜索的延迟随着嵌入的维度线性增长。 选择较低维的嵌入可以最大程度地减少延迟。
- 隐私:金融和医疗保健等敏感领域严格的数据隐私要求需要私有化处理。
一般我们现在可以选择的embedding模型有:
- BGE:这是国人开发的中文embedding模型,在HuggingFace的MTEB(海量文本Embedding基准)上排名前2,实力强劲;
- M3E:也是国人开发的中文embedding模型;
- 通义千问的embedding模型:是1500+维的模型;
- Text-embedding-ada-002:这是OpenAI的embedding模型,1536维,我感觉上应该是目前最好的模型,但是它在MTEB上排名好像只有第六;
- 自己训练embedding模型:当然,训练是基于一个既有embedding模型的,在原来的基础上提升3%-10%的性能。
四、检索环节
检索环节技术含量依然很高,检索优化一般分为下面五部分工作:
- 查询重写:一旦查询通过输入保护,就将其发送到查询重写。 有时,用户查询可能含糊不清或需要上下文才能更好地理解用户的意图。 查询重写是一种有助于解决此问题的技术,转换用户查询以提高清晰度、精确度和相关性。
- 根据历史重写:系统利用用户的查询历史记录来了解对话的上下文并增强后续查询。 我们以信用卡查询为例。查询历史:“你有多少张信用卡?”,“白金卡和金卡信用卡有年费吗?”,“比较两者的特点。”我们必须根据用户的查询历史来识别上下文演变,辨别用户的意图和查询之间的关系,并生成与不断变化的上下文相一致的查询。重写查询:“比较白金信用卡和金卡信用卡的功能。”
- 创建子查询:由于检索问题,复杂的查询可能很难回答。 为了简化任务,查询被分解为更具体的子查询,这有助于检索生成答案所需的正确上下文。如给定查询“比较白金信用卡和金卡信用卡的功能”,系统会为每张卡生成子查询,这些子查询重点关注原始查询中提到的各个实体。重写的子查询:“白金信用卡有什么特点?”,“金卡信用卡有什么特点?”
- 创建类似的查询:为了增加检索正确文档的机会,我们根据用户输入生成类似的查询。 这是为了克服检索在语义或词汇匹配方面的局限性。如果用户询问信用卡功能,系统会生成相关查询。 使用同义词、相关术语或特定领域的知识来创建符合用户意图的查询。生成的类似查询:“我想了解白金信用卡”->“告诉我白金信用卡的好处。”
- 元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度。比如,我们问“帮我整理一下XX部门今年5月份的所有合同中,包含XX设备采购的合同有哪些?”。这时候,如果有元数据,我们就可以去搜索“XX部门+2023年5月”的相关数据,检索量一下子就可能变成了全局的万分之一;
- 图关系检索:如果可以将很多实体变成node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。特别是针对一些多跳问题,利用图数据索引会让检索的相关度变得更高;
- 检索技术:前面说的是一些前置的预处理的方法,检索的主要方式还是这几种:
- 相似度检索:业界有六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等
- 关键词检索:这是很传统的检索方式,但是有时候也很重要。刚才我们说的元数据过滤是一种,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率。据说Claude.ai也是这么做的;
- SQL检索:这就更加传统了,但是对于一些本地化的企业应用来说,SQL查询是必不可少的一步。
- 重排序(Rerank):很多时候我们的检索结果并不理想,原因是chunks在系统内数量很多,我们检索的维度不一定是最优的,一次检索的结果可能就会在相关度上面没有那么理想。这时候我们需要有一些策略来对检索的结果做重排序,比如使用planB重排序,或者把组合相关度、匹配度等因素做一些重新调整,得到更符合我们业务场景的排序。因为在这一步之后,我们就会把结果送给LLM进行最终处理了,所以这一部分的结果很重要。业界常用的有RankVicuna, RankGPT和 RankZephyr
- 最大边际相关性 (MMR):MMR 增加多样化和相关的项目集,从而最大限度地减少冗余。MMR 不是仅仅专注于检索最相关的项目,而是实现了相关性和多样性之间的平衡。 这就像在聚会上向人们介绍朋友一样。 最初,根据朋友的偏好来识别最匹配的人,然后会寻找稍微不同的人,此过程持续进行,直到达到所需的引入数量。
- 自动剪切:通过检测分数相近的对象组来限制返回的搜索结果数量。原理是分析搜索结果的分数并识别这些值的显著跳跃,这可以表明从高度相关的结果到不太相关的结果的转变。
- 句子窗口检索:检索过程获取单个句子并返回该特定句子周围的文本窗口。 句子窗口检索确保检索到的信息不仅准确而且与上下文相关,提供围绕主句的全面信息。
- 子查询:可以在不同的场景中使用各种查询策略,比如可以使用LlamaIndex等框架提供的查询器,采用树查询(从叶子结点,一步步查询,合并),采用向量查询,或者最原始的顺序查询chunks等;
- 查询路由:在处理多个索引时,查询路由被证明是有利的,它将查询定向到最相关的索引以实现高效检索。 这种方法通过确保每个查询都定向到适当的索引来简化搜索过程,从而优化信息检索的准确性和速度。在企业搜索的背景下,数据从不同的来源(例如技术文档、产品文档、任务和代码存储库)建立索引,查询路由成为一个强大的工具。 例如,如果用户正在搜索与特定产品功能相关的信息,则查询可以智能地路由到包含产品文档的索引,从而提高搜索结果的精度。
- HyDE:可以使用 HyDE 技术来解决检索性能差的问题,特别是在处理可能导致查找信息困难的短查询或不匹配查询时。这是一种抄作业的方式,生成相似的或者更标准的prompt模板。
五、生成(Gen)
- 可使用的框架有Langchain和LlamaIndex。
- 存在多种用于改进 RAG 输出的prompt技术,后面专门研究。
六、输出保护
输出保护的功能与其输入保护类似,但专门用于检测生成的输出中的问题。 防止生成可能与品牌价值观不符的不准确或道德上有问题的信息,通过积极监控和分析输出,确保生成的内容保持事实准确、道德合理且符合品牌准则。
七、缓存
缓存提示及其相应的响应,以便能够后续检索它们使用, 这种战略性缓存机制使 LLM 应用程序能够加快响应速度,并具有三个明显的优势。
- 增强生产推理:缓存有助于在生产过程中进行更快且更具成本效益的推理。 某些查询可以通过利用缓存的响应来实现接近零的延迟,从而简化用户体验。
- 加速开发周期:在开发阶段,它消除了重复调用相同提示的 API 的需要。 这会带来更快、更经济的开发周期。
- 数据存储:利用存储的提示响应对可以简化基于累积数据的模型优化。
八、存储
需要解决存储向量、文档、聊天记录、用户反馈等数据,后期详细展开介绍。
总结
LLM技术浪潮催生了众多创新技术。要使这些技术在企业应用中发挥最大效用,需要我们深入研究并持续实践,以期打造出高质量的解决方案。
参考:
https://www.rungalileo.io/blog/mastering-rag-how-to-architect-an-enterprise-rag-system
https://mp.weixin.qq.com/s/37tKVQbxenVVBAeMZ334aQ
https://arxiv.org/pdf/2401.05856