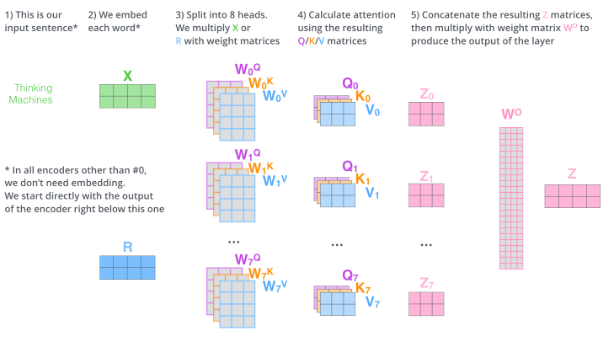
今天这次测评显卡对 AI 模型推理到底有没有加速作用?
01 细节
使用显卡:4090D
待测 AI 模型:whisper 音频转文字 AI 模型
被测数据:10s 长度音频、30s 长度音频
02 背景
在上次音频转文字时,没有使用显卡加速,昨天刚搞定用显卡帮忙推理加速,今天就来测试一下前后对比。
有没有显卡,到底对 AI 模型推理的加速效果如何?
whisper 一共有八个模型,分别是 tiny,base,small,medium,large,large-v1,large-v2,large-v3。
所以需要分别测试一下不同模型的效果。
03 无显卡
首先来看 10s 长度的音频,无显卡加速,纯 CPU 推理。
虽然 tiny 和 base 时间很短,但是显而易见,还是会识别出错别字,这就是牺牲了智商,换来了速度。
从 medium 这个模型开始,识别字准确率上来了,但是消耗时长(29s)也陡增,几乎是原音频长度(10s)的 3 倍了
04 有显卡
接下来我们来看有显卡推理加速的版本,依旧还是 10s 长度:
有显卡推理加速时,基本上 large 系列的模型,都维持在 18s 左右,不到原音频长度的 2 倍。
相比于原来动辄 30-50s 左右,时长已经降低很多了。
05 进一步对比
此时,不确定原音频长度对推理时长的影响有多大,我们直接换个时长的音频,30s,再次推理看时长。
当我把三次测试的结果放一起时,一目了然。
蓝色是无显卡,10s 音频,红色是有显卡,10s 音频,橙色是有显卡,30s 音频。
06 结论
在保证准确度的前提下,比如都使用 large 系列的模型,那么无显卡的平均时长为:42.00s,有显卡的平均时长:18.37s
也就是说,使用 GPU 后的平均时长相比于不使用 GPU 时的平均时长,提高了约 56.26%。
那么综合图片的评测结果来看,推理速度确实是加快了很多,也总算发挥了我这个显卡的价值了。
最后,无论是哪种情况,都推荐使用 whisper 的 large-v2 模型,纵向对比准确率最好,横向对比平均时长最短。
来源:想象力AI