前言
人工智能(AI)不再只是科幻电影中的桥段,而是正以前所未有的速度改变着我们的世界。随着大规模语言模型(LLM)系列的崛起,结合高度智能的(Agent)与精心设计的(Prompt),AI 技术正步入一个全新的进阶实战阶段。
本文将带您深入探索这一前沿领域,揭秘如何运用 LLM 大模型、智能体 Agent 与提示词 Prompt,共同编织出未来智能生态的宏伟蓝图。
No.1 实操环境准备
FastAPI(极简、快速、高性能Web框架)+redis(数据缓存、存储服务)
设置如上-会话存储的 hash 结构:具体的 value 即回答的 N 条真实记录(可结合实际会话ID进行关联),到这里准备工作就已经完成了。
No.2 项目工程搭建
建立 Python Project:这里 LLM 采用 KIMI(moonshot):
模型版本选择(moonshot-v1-32k)+ 精妙提示词(prompt)设定(高质量的提示词可以帮助模型理解人类的目标,换言之人类直接向模型提出命令或一条通向目标的推理路径。设计一个更有效的交互策略,使得模型生成的内容能符合人的意图和需求)
输入如下命令,启动开发服务器并在代码变更时自动重新加载。
uvicorn main:app --reload --host 127.0.0.1 --port 8888
这样,就能够提供对外的 API 接口出来了,接口调用效果如下:
当然,我们也可以使用 Restlet Client 进行 Rest API Testing:
No.3 智能问答调试
这里,我们给定一些日常话题来看看咨询效果:
因为在之前调试的时候,有些问题已经有了记忆属性,但还是能够看出 AI 可以精准理解我们的输入意图。
对应在 Jupyter Notebook 中的回答效果如下:
接下来,以一个真实案例嵌入:多语-国际化,这里选择一个在多语言环境存在不一样词性的词。
输入请帮我用中文繁体翻译下这段话:
即将发布一个带有新发型妆造的广告
对应 Jupyter Notebook 回答:可以看出对“发”这个词依旧准确地给出了答案。
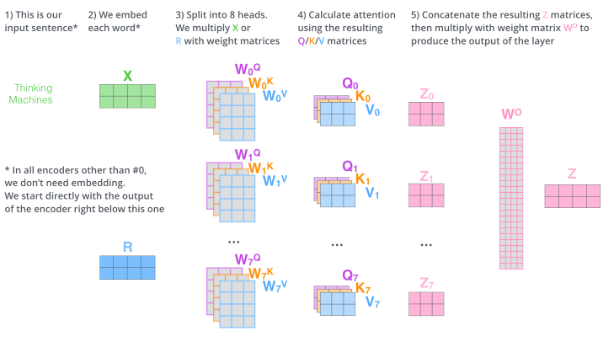
诚然,Encoder-Decoder的过程:从信息的压缩与抽象->信息的还原与创造。
Encoder 它能够将图像、文本等复杂数据转换成高维向量空间中的特征表示,这些特征既保留了原始数据的核心信息,又便于后续的模型处理与理解。Decoder 它负责将 Encoder 处理后的数据还原回人类可理解的形式,无论是文字、图像还是声音,并且它还能在解码过程中融入创造力,通过生成对抗网络(GANs)等先进技术,生成全新的、逼真的内容,如高清图像、逼真语音等。架构,这一架构在机器翻译、语音识别、图像生成等众多领域展现出了惊人的能力。以机器翻译为例,输入源语言的句子经过 Encoder 编码成一系列向量,再由 Decoder 解码成目标语言的句子,整个过程流畅自然,几乎达到了人类翻译的水平。架构也被广泛应用于环境感知与决策制定。车辆通过摄像头、雷达等传感器收集到的海量数据,经过 Encoder 处理后提取关键信息,再由 Decoder 转化为车辆的控制指令,实现安全高效的自动驾驶。
Ok,now,那我们来继续检测一下上下文联想效果:看看之前咨询的问题,在其背后是如何经过决策并将答案呈现至用户眼前的?
*温馨提示*:上述case经过多次调试-调优过程,对背后技术实现原理感兴趣的可联系我一起探讨
来源:每天译点晓知识