大模型的能力进步将对很多领域产生颠覆式影响,客服场景同样也不例外。作为人工智能技术早已渗透多年的场景之一,无论是面向内部员工的自助服务还是面向外部客户的自助服务,智能客服在企业都有着普遍的应用需求。
在大模型出现以前,智能客服主要是基于预设的规则和知识库进行问题解答,这种方式虽然在处理常见和标准问题时效率较高,但也存在显著问题:
第一,有限的理解能力。基于规则的智能客服通常只能理解预设的问题和关键词。这意味着它们很难处理用户以非标准方式表达的问题,如使用方言、行业术语或者含糊其辞的表述。用户提问如果未命中正确的关键词或短语,系统可能无法提供正确的答案。
第二,缺乏上下文感知。传统的智能客服系统通常无法处理涉及多轮对话的上下文信息。这导致在一次会话中,即便是连续的问题,也需要用户重复提供信息,因为系统无法“记住”前一条查询的内容。
第三,交互性和灵活性不足。传统智能客服系统通常按照固定的模式回应用户,缺乏灵活性和自然流畅的交互体验。它们很难根据对话的发展自然地调整回应,使得对话显得机械和僵硬。
第四,知识运维成本高。当出现新的产品特性、政策更新或者市场变化时,基于规则的系统需要人工更新知识库和规则,这种依赖大量手动维护的方式不仅成本高、效率低下,而且容易出错。
第五,个性化服务不足。传统智能客服系统主要基于一般性解答,它们往往无法提供针对个别用户特定需求的个性化服务。对所有用户的回答往往是标准化的,缺乏针对性和个性化的深度。
这些正是大模型可以带来变革的方向。大模型加持下,智能客服可以实现:
第一,语义理解能力增强。大模型基于超大规模数据训练,能够理解并处理复杂的语义结构,使得智能客服能够更准确地解析和理解用户的自然语言输入。这些模型利用上下文信息和深层次的语言模式,能够精确识别用户意图,改进意图识别流程。
第二,情绪识别与应对。大模型通常集成了情绪识别技术,能够根据用户的语言和表达推断其情绪状态,从而调整回应策略。这种能力使得智能客服在处理客户的问题时更具同理心和人性化,能更有效地管理用户的情绪和满足他们的需求。
第三,更自然的对话体验。大模型能够生成流畅、自然的语言,使得用户与智能客服之间的对话更类似于人与人之间的交流。这种改进不仅增强了用户体验,提升了用户满意度,还有助于构建用户的长期信任和依赖。
第四,知识自动更新。大模型具备持续学习能力,可以通过不断的数据训练来迅速适应新的市场动态、产品变更或政策更新。这使得智能客服系统始终能提供最新、最准确的信息和服务。
第五,个性化服务体验。通过分析用户的历史交互、偏好和上下文对话信息,大模型能够提供定制化的建议和解决方案。个性化服务不仅限于内容的相关性,还包括回应的语气和风格,使得每位用户得到定制化的服务。
从底层核心NLP技术的历史演进来看,基于规则的聊天机器人代表了智能客服演进的起点,随着机器学习技术的发展,基于规则的聊天机器人逐渐被基于模式匹配的聊天机器人所取代。而相较于基于规则的聊天机器人,机器学习技术驱动的聊天机器人具有了一定程度的智能,可以处理一些复杂的对话场景;深度学习技术的兴起使得聊天机器人进入了一个新阶段,深度学习技术驱动的聊天机器人采用了RNN(循环神经网络)、GAN(生成对抗网络)等混合AI技术,使聊天机器人能够进行更加自然和人性化的交互。
大模型技术出现后,聊天机器人的核心技术进一步升级,新技术的出现并不是要完全淘汰之前的技术实现方式,而是在某些模块上进行优化,以实现更好的效果,在人工智能技术组合基础上实现整体迭代。例如,大模型虽然提升了聊天机器人的自然语言理解模块,但对于特定任务仍然可以使用正则表达式等基于规则的逻辑实现。
从智能客服的完整流程来看,大模型在核心环节均有渗透:
根据沙丘社区的调研,当前基于大模型的智能客服解决方案在以下环节渗透率最高且发挥出明显价值:
• 对话内容总结:基于大模型的总结能力,可以为人工客服提供坐席辅助、工单预填、前情摘要等能力,提升坐席人员的工作效率,降低客户通话时长。
• 知识资产构建:基于大模型的内容创作、总结、分类等能力,可以从对话记录等非结构化文档数据进行智能的知识抽取,自动完成知识标注和知识维护,这些知识点将被用于知识管理流程和系统中,然后补充到企业知识库中。
• 机器人坐席:大模型提高了机器人客服的意图理解和内容分类能力,这是机器人客服更像“人”一样与用户对话的核心能力。此外,内容创作和增强、语气/说话风格、总结等能力的结合,使得机器人坐席能够有效理解和分析自然语言,与用户进行更加自然、流畅的交互,提升用户体验。
从实现路径上看,企业利用大模型建设智能客服的思路主要分成两种:
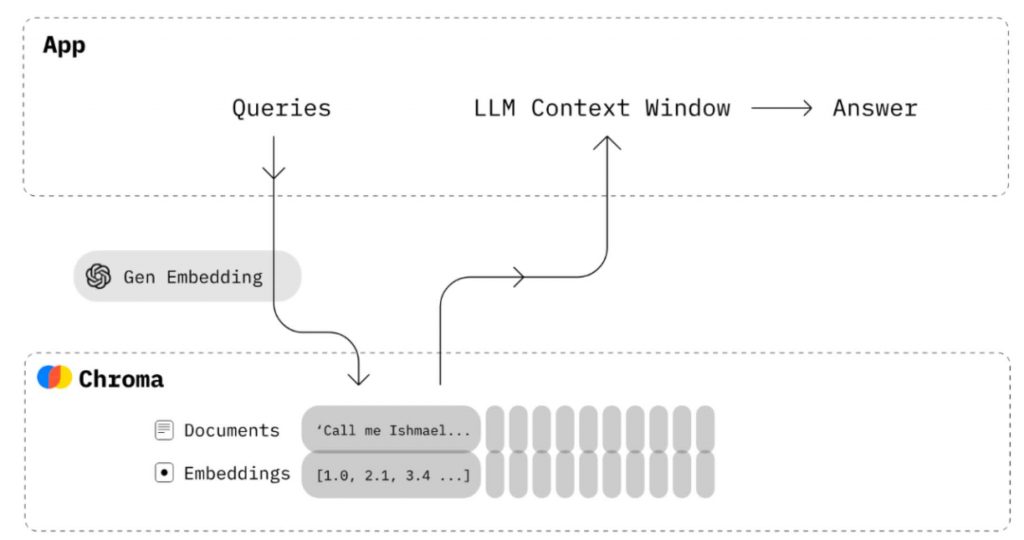
第一种:RAG思路。将领域知识构建到向量数据库中,当用户和问题系统进行交互时前置检索到领域知识然后提供给大模型使用。
第二种:Fine-Tuning思路。通过对大模型本体的更新,将知识更新进去,需要对模型调优、重新部署,甚至需要大量GPU重新训练模型。
RAG思路相当于将现有知识进行外置存储或检索,优势在于更加方便集成现有知识、动态更新知识成本低、通过上下文限定一定程度消除模型幻觉;但Fine-Tuning思路的优势在于除了加入更新后的知识外,还可以影响模型生成内容的风格。
在企业实际应用时,应选择两种思路的融合,从而提供更优的解决方案,根据使用场景,充分发挥两种实现路径的优势。
很多企业现已将客服场景作为大模型落地探索的重要场景之一,通过沙丘社区对企业用户的调研,为企业用户总结出三个容易掉入的“陷阱”以及应对方案:
陷阱1:将大模型作为答案,寻找可以解决哪些问题
很多企业一开始将大模型作为“答案”,倒推可以解决哪些“业务问题”,这样做不仅会浪费资源,还可能将精力耗费在不符合组织战略目标的行动上。
对此,企业必须从已知的业务挑战入手,寻找正确的解决方案。对大多数企业而言,最好的切入点是参考智能客服厂商推出的带有大模型功能的产品或解决方案。
陷阱2:人员和流程还没有准备好,就开发产品工具
即使对于技术公司来说,在现阶段尝试内部开发大模型解决方案也会面临巨大风险。当前大模型技术正在快速发展,企业选择自建而非直接购买可能会导致产品工具开发出来后过时、开发成本过高或者无法达到满足投资合理性的最低标准。
企业将技术作为首要考虑因素而忽视人员技能提升和流程升级,会推迟价值实现的时间。
陷阱3:低估了大模型偏见对应用的负面影响
大模型的偏见问题会显著增加智能客服在面向用户使用时的风险,尤其是对准确率要求较高的直接对客场景。企业需要确定大模型偏见在组织环境中的含义,采用严格的方法监测、衡量并减轻其影响。