虽然这种做法在很大程度上包揽解决了大部分的运营问题,但这种模式仍旧有一些问题:
- 问题及解决方案得不到自动沉淀,如果想沉淀faq,依赖值班手动进行记录,耗时耗力。
- 问题解答要求值班同学对问题所涉领域有足够了解,才能找到具体对接同学定位问题。
- 群消息内容繁杂,消息有时容易吞没,依赖值班同学“爬楼有道”。
可见,依赖人工干预和手动记录,不仅耗费大量时间和人力,而且容易出错和遗漏,基于此,一个可智能对话、可针对性一键拉群、支持FAQ沉淀的智能客服系统诞生了。本文就将带你一起了解下面向平台的智能客服系统的落地实践之心路历程。
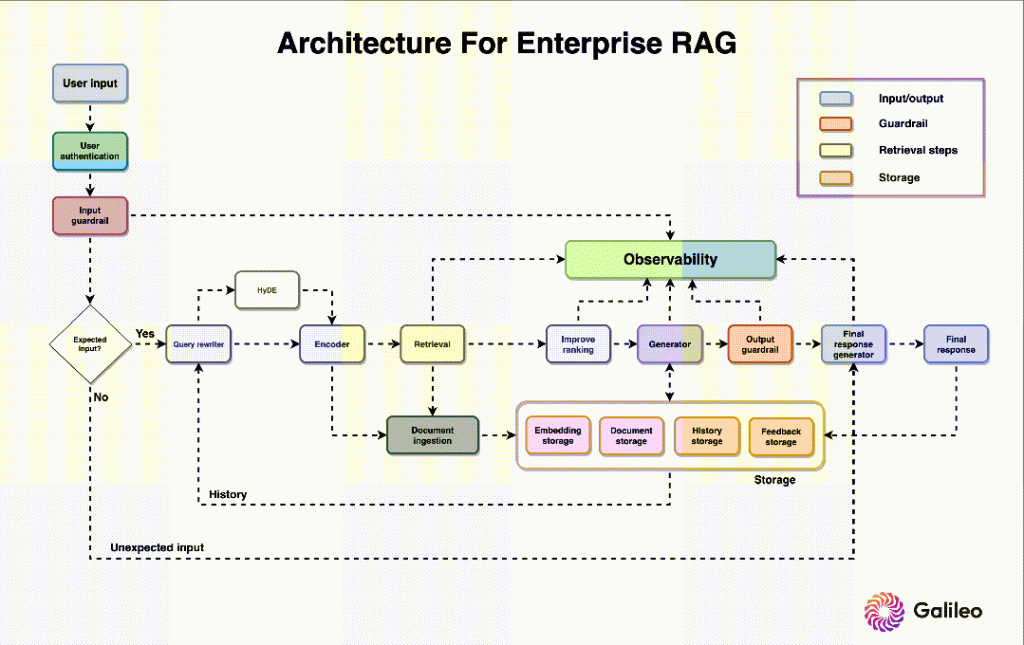
- 对话界面
- 会话状态机
- 数据源模型
- 统计汇总后台
- 接入配置
- 对话界面
想要收集运营问题,提供给运营的对话界面不可少。经过对运营使用习惯调研,大部分运营更愿意使用企微原生功能实现对话,而跳转到第三方网页或者在活动后台开启对话窗口的形式,运营都不愿意接受,这也不难理解,毕竟企微是大家日常沟通的集散地。企微目前支持服务号/应用号两种不同的可提供对话页面的形式,由于受限于服务号的“无消息回调”,“人工座席与智能服务不能共存”等问题,最终我们选择了应用号作为人工客服的主要对话入口。
- 会话状态机
后端维护了一整套会话管理体系,会话状态由会话开启、进行中(转人工、未转人工)、已结束组成,每次会话在运营向应用号发消息时开启,在聊天过程中,应用号与后端服务进行交互,通过不同类型的消息事件,触发开启会话、自动收集会话信息、会话识别、会话FAQ匹配、回复用户答案等流程,维护会话状态,并对用户一键拉群、结束会话等请求进行响应。同时,会话状态机维护一个状态的延时消息队列,在用户长时间无响应时进行主动二次确认,并保留对会话自动关闭的机制。
- 数据源模型
这里所说的数据源模型,主要是指在识别用户消息内容后,针对消息内容,进行合理回复的底层数据源选型模型,目前本套智能客服回复支持两种模型,一种是基于ES搜索的,另一种是基于类似ChatGPT的专业领域学习模型,使用OpenAI API对用户的问题进行向量分析并回答。
另一种基于自然语言处理和机器学习的问答处理模型,其特点就是问题回答更自然、更人性化,它可以对用户问题进行预处理,对原始答案进行加工。但是其缺点在我们的智能客服项目中也体现的比较明显,在我们FAQ库、对话信息收集不足够丰富的情况下,模型训练的准确性并不高,甚至模型会有“自由发挥”空间,这对于我们听话的运营来说实属灾难,可想,运营跟着智能客服一顿操作,最后发现原来这都是智能客服的YY时,大概运营心中会有一万只羊驼经过吧。
基于此,我们调整了模型思路,基于已有信息进行相似度模型训练,我们在这里引入simbert模型,其最大的优势在于在特定专业学习领域里,准确率比其他模型都高,自然我们也不会放弃“ChatGPT”,只不过它更多的是在训练数据足够的情况下,对问题进行极限兜底。
同时,为了保证训练数据的补给,我们也打通了一条离线数据补给流,对话界面收集到的FAQ及对话信息会通过离线任务同步给训练模型,让训练模型不断“精进自我”,提高回答的准确率。
目前智能客服支持两种数据模型的开关控制,随时随地随意切换。
- 统计汇总后台
为了方便对所有会话数据进行管理、review、统计,我们提供了一套可视化的管理后台,这个后台的特色有几点:
一是lowcode,使用我司LEGO系统,在后端同学一顿拖拖拽拽,稍微改动后,一整套可克隆的后台就生成了;
- 接入配置
事实上,在做完这套智能客服系统之后,整个系统设计受到了很多兄弟团队的青睐,比如日常也要处理用户问题的前端基建团队,数据库DBA团队,看来大家对于日常FAQ收集、用户问题解答等工作都在寻求更加低成本、可持续的解决方案。所以我们在Q2对整套系统进行了开放化开发,开放后我们支持多团队应用号接入,所有团队拥有同样的会话状态机管理、底层数据源的灵活选择,并实现了各团队数据隔离,可一键克隆后台管理页面等功能。
目前在接入流程上,主要有如下几步:
- 提供配置信息;比如:企微应用号AppSecret等基本信息,这主要是为了方便使用企微提供的API接口实现消息解析与回复,同时需要提供一键拉群的值班信息、问题收集模板配置等。
- 回调接口绑定;如果接入团队想要使用应用号作为对话界面,则需要将统一的回调接口绑定在企微应用上,方便对对话进行收集、解析、回复。当然,我们的接口,也提供给有定制化对话窗口开发的团队,方便对websocket等形式的对话界面进行开发。
- 一键克隆后台管理页面;对后台管理界面进行克隆并稍加修改,便能满足团队大部分诉求。
至此,稍加调试,其他团队就可以方便的接入智能客服,完成一系列日常问题处理的闭环工作,包括智能会话管理、问题FAQ收集、语言模型训练等。
- 更加开放,可以利用企微应用号的回调能力开发智能客服系统,但同时也提供SDK服务,将能力提供给所有有需要的公司内部团队使用,不限于帮助团队灵活的进行对话界面的定制化开发。
- 接入平台化,现在要接入整个智能客服系统,需要人工对接,后续把对接流程线上平台化,增加一些审核机制,就可以方便的实现服务一键接入。
- 对转人工进行优化,如果团队使用企微应用号形式进行接入,那么就一定会受限于企微的既有功能,在用户转人工后,需要单独拉群间接实现摇人,整个对话无法在应用号内实现闭环解决,跳出带来的一是用户体验,二是拉群太多增加了管理成本。这一部分我们考虑“花钱”解决,比方说能否以公司身份出面向企微提需,提供更加灵活的功能。
最后感谢大家耐心的读到了这里,希望你能有所收获,哪怕一点点,哈哈。
来源:架构师