OCR技术在基金行业的运用场景众多,许多场景下的识别技术已趋向成熟,如各类通用证照、通用票据的识别准确率已达到99%。然而,在基金行业的实际业务应用中,大量耗费人力的是相对复杂的业务文档资料处理。例如:直销柜台账户、交易表单、资金指令、基金公告等业务表单的解析和处理。传统的OCR技术无法对上述复杂表单的内容识别及信息提取能力进行有效处理。由于涉及图像增强、印章识别、手写签名比对、复选框解析和复杂表格识别技术,使得OCR在复杂文档资料的处理方面面临较大的技术挑战。
2.针对非结构化长文档,需要智能化文档处理能力
在基金业务实际业务运营中,除了格式相对固定的表单文件,还涉及大量的长文档和非结构化形式的文档资料,例如基金合同、基金公告等,需要通过AI平台实现文档信息的识别、提取和审核。然而,单纯依靠OCR能力无法解决非结构化长文档的智能处理需求,还需要引入NLP能力,通过训练智能信息抽取模型,从长文档中智能化提取相关信息,为业务系统所用,辅助业务人员实现相关的信息录入、业务审核等工作。因此,AI中台的建设需要引入智能文档处理能力,并与OCR能力相结合,从而解决非结构化长文档的智能处理工作,打造更全面的文本处理智能化AI平台。
3.业务需求灵活多变,需构建可拓展的模型训练能力
基金业务各类凭证及文档资料会随着业务需求或监管制度的变化而不断调整格式,即使识别文件对象的格式没有改变,对模型进行持续优化,不断提升识别效果的需求也始终存在。因此,如何对OCR识别模型、智能文档处理模型的生命周期进行有效管理,从而实现模型的快速更新迭代,是AI平台使用过程中的一大挑战。
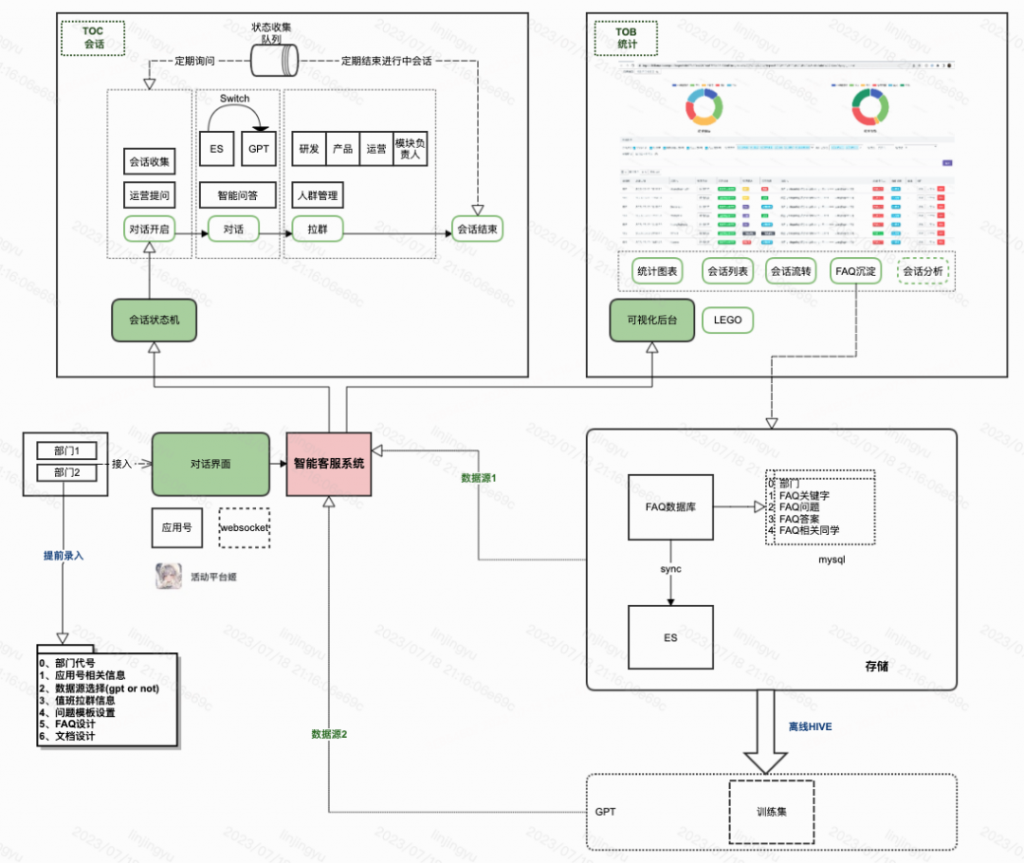
(3)AI标注训练平台。AI标注训练平台是基于AI智能处理引擎的底层核心技术,实现对文档的类型管理、AI标注管理,以及基于深度学习算法等进行AI模型训练和AI模型管理。充分利用AI标注训练平台对不同的基金文件的类型和核心字段进行管理识别,用于上层的抽取应用。
(4)AI服务能力层。AI服务能力层主要封装完整的AI能力组件,可为业务应用层的业务需要所调用,主要包括OCR图像识别和智能文档处理能力,如图像增强识别、签名识别、表格解析、长文档抽取、版面解析、文档审核等可视化的AI系统服务能力,上层业务系统可按照业务需求进行调用。
(5)业务应用层。AI服务能力层主要涉及各类业务系统的AI服务接口调用,通过AI服务层的API服务及iframe页面嵌入的方式,将AI能力有效地嵌入至业务系统,实现业务作业自动化,通过AI赋能促进运营、投顾、投研等业务数字化转型。
2.针对复杂文档的OCR技术优化
通过在AI中台现有OCR能力的基础上构建更智能化、可拓展的OCR识别处理能力,优化针对复杂文档的OCR识别能力,以实现更加高效、精准的OCR服务,主要包括以下优化场景。
(1)AI平台实现对图像的增强处理,包括图像切边增强、弯曲矫正、透视矫正、去摩尔纹、水印去除、阴影处理、手写文字擦除等预处理,提升待识别图像质量。
(2)平台实现印章识别能力,可涵盖日常工作中常见的印章内容识别,印章类别包含公章、财务章、法定代表人章、发票专用章、合同专用章等类别;颜色包含灰度印章、红色印章等;形状包含圆形、椭圆印章等。
(3)平台实现手写体文字的检测,可识别和定位文档中手写体文字的位置并生成对应的图片,接入数据库中的签名,人工可比对两份签名图片。
(4)平台实现复杂表格的解析,可将有框表格、无框表格、半框表格、倾斜、透视变化等多种复杂表格实现精准识别及表格数据的解析,并支持人工对表格内容进行编辑,包括但不限于绘制表格、调整表格、删除表格、新增长线、新增短线、合并单元格、删除线条、跨页合并/拆分、撤销操作等操作,方便业务人员支持一键定位表格解析内容,直观查看解析结果。
3.构建非结构化文档智能处理能力
在基金业务实际业务运营中,涉及大量的内外部非结构化长文档资料的处理工作,例如基金合同、基金公告等材料,需要通过AI平台实现文档信息的识别、提取和审核。AI中台通过构建非结构化长文档智能处理能力,实现非结构化文档的智能版面分析,并且训练智能信息抽取模型,从长文档中智能化提取相关信息为业务系统所用,大幅提升工作人员在长文档资料处理方面的工作效率。
(1)平台可全文识别扫描件、PDF、Word等各种格式文档中的段落、表格、目录、图片、标题等信息,支持前端自定义版面解析模型,不同的文件可通过不同的版面解析参数进行解析。
(2)构建面向基金行业的专用文档识别抽取模型,基金合同、基金公告、基金申购确认单、基金交易确认单等文档的智能识别和关键信息提取。
4.构建可拓展的AI模型训练能力
基金业务各类凭证及文档资料会随着业务需求或监管制度的变化而不断调整格式,AI中台需要具备训练模型自定义能力以及对模型进行持续优化的能力。AI中台充分考虑到OCR识别模型、智能文档处理模型的生命周期有效管理,从而实现模型的快速更新迭代。
AI平台可通过可视化的方式训练OCR及NLP应用模型,提供划选、框选、字段拼接等5种简易标注方式实现训练数据的预标注能力,大大减少用户标注工作量。平台预置序列标注、模板匹配、表格抽取、规则匹配等多种算法,灵活适配不同场景下的AI模型训练方式。自动计算准确率、召回率、F1值、通用准确率等指标,为模型提供参考依据,支持对每一个抽取字段进行评估结果量化统计,方便开发人员快速判断模型效果,以支撑快速实现模型从开发训练到落地应用(如图2所示)。
鹏华基金企业级AI平台建设的核心理念是形成规范统一的技术及应用服务架构,需要从资源使用、数据治理、AI原子能力构建、AI服务能力构建、应用赋能等多个维度进行架构设计及规范制定,并需要充分考虑到平台未来可能扩展的其他AI能力,实现面向全公司的资源与服务共享,这需要在AI平台建设过程中,始终坚持资源可共享、模型可复用、需求可拓展、系统可运维的原则。同时,在各类业务系统的设计过程中,要对涉及AI处理的相关需求进行充分统筹考虑,纳入AI平台整体范畴,避免AI能力单点建设及重复建设,造成开发资源浪费。
2.注重基础数据治理工作,积累高质量的训练数据
AI模型的训练离不开高质量的训练数据,可获得的训练数据量和数据质量将直接影响AI模型的预期训练效果。基金公司具有天然的数据资源优势,在日常内外部业务运营过程中,会产生存储海量的业务数据。但不同的数据往往是分布式存储于各类业务系统中,通过规划数据中台可将各类数据进行归集,以便AI中台进行调用。此外,大量的数据均以非结构化的形式存储,训练AI模型在使用这些数据时还需要对其进行标注,完善AI模型训练数据的标注规范也是一项重要的工作。数据标注工作需要对业务充分的了解,因此,除科技部门外,应用部门参与或指导数据标注工作也非常必要。在AI项目建设中,业务部门也需要加大人力资源投入,组织人员持续开展数据标注工作,以支撑算法模型训练所需。
3.探索大模型等新技术,拓宽AI平台的应用边界
当前大语言模型、深度学习等技术快速发展,尤其是基于大语言模型的各类AI应用探索也取得了快速突破,AI平台未来能力的拓展也需要充分考虑到大语言模型对传统AI能力的赋能,通过大语言模型能力挖掘出更多的AI应用场景。例如通过大语言模型的预训练能力,可替代传统的NLP算法,实现文本抽取、文本分类、智能标签、智能摘要这些基础性的NLP任务,并可拓展基于大语言模型能力,拓展知识问答、文档翻译、文档创作等智能应用场景。通过前沿AI技术的加持,结合传统AI技术的应用深化,持续加强诸如大模型、深度学习方面技术资源和人才资源积累,积极探索新技术的应用场景,不断拓展和升级AI平台的能力范围应用边界,这也是在数字化时代保持核心竞争力的重要手段。
来源:金融电子化