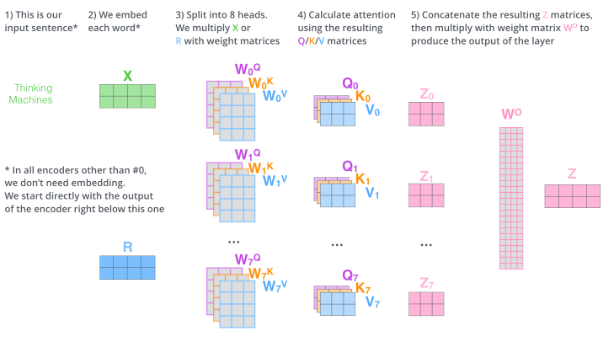
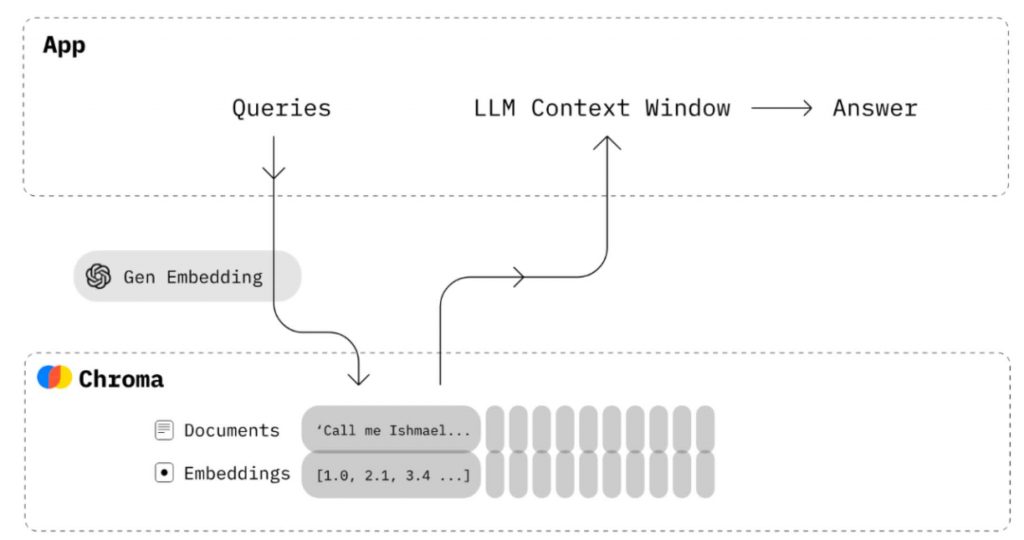
本文主要由文章《15 Advanced RAG Techniques from Pre-Retrieval to Generation》总结并添加了一些自己的理解。
检索增强生成 (RAG) 是一种强大的技术,它将信息检索与生成式 AI 相结合,以产生更准确、上下文更丰富的响应。本文将探讨 15 种高级 RAG 技术,以提高生成式 AI 系统的输出质量和整体性能的鲁棒性。这样做使本文能够测试和识别从预检索到生成的适当优化,本文所提到的优化点大多数基于下图的流程。
一般来说,传统的 RAG 系统经常会遇到以下问题:
-
信息密度:检索到的文档可能不包含足够的相关信息。 -
检索准确性:系统可能无法检索最相关的文档。 -
响应质量:生成的响应可能不准确或缺少上下文。先进的 RAG 技术通过优化 RAG 管道的每个阶段来应对这些挑战,从而实现:更高的系统效率、更好地满足用户需求、最优语义搜索以及更相关准确的回复。
RAG 中,召回是一个核心步骤,按照不同优化策略和召回的前后关系,优化策略可分以下几类:
-
预检索优化 -
检索/召回策略 -
检索后优化 -
生成优化
预检索优化
预检索优化主要包括提高数据索引或知识数据库中信息的质量和可检索性。由于每个系统依赖于不同性质的信息,预检索优化策略不一定是万能的。比如为金融系统设计的优化策略在旅游机器人中可能不太有效。预检索优化包括以下方法
-
使用 LLM 提高信息密度 -
使用分层索引检索 -
创建假设性问答对 -
使用 LLM 对信息进行去重 -
测试并优化最优分块
▶使用 LLM 提高信息密度
在存储数据前使用 LLM 处理、清洗以及对数据进行打标。这种改进是因为来自异构数据源(例如 PDF、抓取的网页数据、音频转录)的非结构化数据不一定是为 RAG 系统构建的,导致信息密度低、噪声数据、信息重复等
信息密度低迫使 RAG 系统在 LLM 上下文窗口中插入更多的块,以正确回答用户查询,从而增加了 token 的使用和成本。此外,信息密度低会稀释相关信息,以至于 LLM 可能会给出错误的回答。GPT-4 在使用少于 70,000 个 token 时似乎对这个问题有相对的抵抗力,但其他模型可能没有那么强的鲁棒性。
比如当原文本来源于网页时,原始 HTML 包含了大量无关信息(例如 CSS 类、页眉/页脚导航、HTML 标签等冗余信息)。即使在程序化地剥离了 CSS 和 HTML 之后,信息密度仍然很低。因此,为了提高块中的信息密度,本文尝试使用 GPT-4 作为事实提取器,从文档中提取相关信息。
对应的 prompt 中,system 指令为:
You are a data processing assistant. Your task is to extract meaningful information from a scraped web page from XYZ Corp. This information will serve as a knowledge base for further customer inquiries. Be sure to include all possible relevant information that could be queried by XYZ Corp's customers. The output should be text-only (no lists) separated by paragraphs.以上流程中,原始 HTML 约有 55000 tokens,而使用 GPT4 提取后的信息约有 330tokens,在降低噪声的同时大大提高了信息密度。
值得注意的是,使用 LLM 提高信息密度是伴随着风险的,即可能导致部分关键信息丢失。
▶使用分层索引检索
由 LLM 生成摘要并对摘要进行检索可以使得检索过程更为高效。上节使用 LLM 提高信息密度的方法类似于无损压缩,而使用 LLM 生成摘要更像有损压缩。在大型数据库的情况下,一种有效的方法是创建两个索引 — 一个由摘要组成,另一个由文档块组成,并分两步进行搜索,首先通过摘要过滤掉相关文档,然后在此相关组内进行搜索。
▶创建假设性问答对
在数据准备阶段,embedding 的对象是原始文本(answer),而在请求阶段,embedding 的对象是用户 query。这使得查询的 embedding 和结果的 embedding 是“不对称”的。一种方法是使用 GPT-4 为每个文档生成一系列假设/可能的问题和答案对,然后使用生成的问题作为嵌入检索的块。在检索时,系统将检索问题及其对应的答案并提供给 LLM。因此,查询的嵌入与生成问题的嵌入的余弦相似度可能会更高。
例如,在文档中,某段话的内容可能是从多个角度介绍了 xx 技术的特点,但是未显式地提到特点、有缺点二词。传统 RAG 情况下当用户问到 xx 技术的优缺点时,难以匹配到此段落。而如果为这个段落生成假设性问题:“xxx 技术的优缺点是什么?有什么特点”,此时 embedding 方法就能准确匹配到此段落。
上图展示了对 HTML 提取的信息生成的问答对示例。值得注意的是,提取问答对仍然可能造成一定的数据信息丢失。
▶使用 LLM 对信息进行去重
使用 LLM 作为信息去重器可以提高数据索引的质量。LLM 通过将块提炼成更少的块来去重信息,从而提高获得理想响应的几率。根据具体情况,数据索引中的信息重复可能有助于或阻碍 RAG 系统的输出。一方面,如果生成响应所需的正确信息在 LLM 的上下文窗口内被重复,它会增加 LLM 做出理想响应的可能性。另一方面,假设重复的程度稀释甚至完全挤出了 LLM 上下文窗口中的所需信息,那么用户可能会收到一个无关的回答。
本方案通过在 embedding 空间中对块进行 k-means 聚类来去重信息,以便每个块聚类中的总 token 数在 LLM 的有效上下文窗口内。然后,本文可以任务 LLM 从原始聚类中输出一组新的提炼块,去除重复信息。如果一个给定的聚类包含 N 个块,本文期望这个去重提示输出<= N 个新块,其中任何冗余信息都被去除。
值得注意的是,这种方法可能会使得从块到原文的引用这一信息丢失。
▶测试并优化最优分块
上述技术强调了分块策略的重要性。但最优的分块策略是特定于具体使用场景的,并且有许多因素会影响它。找到最优分块策略的唯一方法是对你的 RAG 系统进行广泛的 A/B 测试。以下是测试时需要考虑的一些最重要因素。
-
embedding 模型的最优输入长度:不同的模型具备不同的最优的输入长度。例如,来自 sentence transformers 的 embedding 模型在处理单个句子时表现出色,而 text-embedding-ada-002 则可以处理更大的输入。chunk 的大小应理想地根据所使用的特定 embedding 模型进行调整,反之亦然。 -
文档的语义信息:根据文档的信息密度、格式和复杂性,chunk 可能需要达到一定的最小尺寸,以包含足够的上下文信息,从而对 LLM 有用。然而,这是一种平衡的艺术。如果 chunk 过大,可能会在 embedding 中稀释相关信息,从而降低在语义搜索中检索到该 chunk 的几率。如果文档没有自然的分割点(例如,用子标题分段的教科书章节),并且文档是基于任意字符限制(例如 500 字符)进行 chunk 分割的,那么关键的上下文信息可能会被拆分开。在这种情况下,应考虑重叠。例如,采用 50%重叠率的 chunking 策略意味着文档中两个相邻的 500 字符 chunk 将有 250 字符的重叠。在决定重叠率时,应考虑信息重复和 embedding 更多数据的成本。 -
模型的总结能力:虽然 GPT-4 似乎能够处理许多大块内容,但小模型可能表现不佳。此外,在许多大块内容上运行推理可能成本高昂。 -
存储成本:embedding 向量必须存储在某个地方,而较小的块大小会导致相同数据量下更多的嵌入,这意味着增加的存储需求和成本。更多的嵌入也可能增加语义搜索所需的计算资源,这取决于语义搜索的实现方式(精确最近邻 vs. 近似最近邻)。
通过对本 RAG 进行 A/B 测试,本文可以评估每个用例的最佳分块策略。本文主要在由 GPT-4 处理的改进信息密集型文档上测试了以下分块策略:
-
1,000 字符的分块,带有 200 字符的重叠 -
500 字符的分块,带有 100 字符的重叠 -
段落(处理后的文档中存在段落分隔) -
句子(使用 spaCy 进行分割) -
假设性问题生成(从上文详细描述的生成的假设性问题索引中嵌入问题)
在构建 AI 助手时,本文发现分块策略的选择并没有太大影响(见下表结果)。1,000 字符的分块策略,带有 200 字符的重叠,表现略优于其他策略(当然,构建不同的应用可能会出现不同的测试结果)。
检索/召回优化
检索优化涵盖了高级 RAG 技术和策略,目标是在推理时提高搜索性能和检索结果,并在检索发生之前进行优化(本质上,也可以是认为检索过程中的优化)。这些策略包含以下几种:
-
使用 LLM 优化搜索请求 -
HyDE:假设性文档 embedding -
使用查询路由
▶使用 LLM 优化搜索请求
搜索系统在搜索查询以特定格式呈现时往往能达到最佳效果。LLM 是一种强大的工具,可以为特定的搜索系统定制或优化用户的搜索查询。为了说明这一点,本文来看两个例子:优化一个简单的搜索查询和一个面向对话系统的查询。
假设一个用户想要搜索 example-news-site.com 上所有关于比尔·盖茨或史蒂夫·乔布斯的新闻文章。他们可能会在 Google 中输入如下内容:(次优的 Google 搜索查询):Articles about Bill Gates or Steve Jobs from example-news-site。可以使用 LLM 来优化这个搜索查询,具体针对 Google,通过利用 Google 提供的一些高级搜索功能。(最优的 Google 搜索查询):"Bill Gates" OR "Steve Jobs" -site:example-news-site.com。
这种方法对于简单的查询是有效的,但对于对话系统,本文需要进一步提升。
尽管上述简单的搜索查询优化可以视为一种增强,本文发现使用 LLM 来优化对话系统中的 RAG 搜索查询是至关重要的。对于一个只能进行单轮对话的简单问答机器人,用户的问题同时也是检索信息以增强 LLM 知识的搜索查询。但在对话系统中,情况会变得更加复杂。以下是一个示例对话:
客户:“你们的定期存款利率是多少?”助手:“我们的利率是 XYZ。”客户:“哪种信用卡适合旅行?”助手:“XYZ 信用卡适合旅行,原因是 ABC。”客户:“告诉我更多关于那个利率的信息。”
为了回答用户的最后一个问题,可能需要进行语义搜索以检索有关特定 XYZ 旅行信用卡的信息。那么,搜索查询应该是什么呢?仅仅使用最后一条用户消息是不够具体的,因为金融机构可能有许多产品会产生利息。在这种情况下,语义搜索可能会产生大量潜在的无关信息,这些信息可能会挤占 LLM 上下文窗口中的实际相关信息。那么,使用整个对话记录作为语义搜索查询怎么样呢?这可能会产生更好的结果,但仍然可能包括关于定期存款的信息,这与用户在对话中的最新问题无关。本文发现的最佳技术是使用 LLM 根据对话生成最优的搜索查询。此场景中用到了一下 prompt:
You are examining a conversation between a customer of Example bank and an Example bank chatbot. A documentation lookup of Example bank's policies, products, or services is necessary for the chatbot to respond to the customer. Please construct a search query that will be used to retrieve the relevant documentation that can be used to respond to the user.这种技术的一个变体是查询扩展,其中由 LLM 生成多个子搜索查询。这种变体在具有混合检索系统的 RAG 系统中特别有用,该系统结合了来自不同结构的数据存储(例如,SQL 数据库+独立的向量数据库)的搜索结果。其他提示工程技术如step-back prompting``和HyDE也可以与这种方法结合使用。
▶HyDE:假设性文档 embedding
预检索优化策略中提到了查询和文档内容的 embedding 可能存在不对称的问题。通过应用 HyDE,我们还可以在检索阶段实现更大的语义相似性。
预检索优化中的方法是为每个段落生成对应的问答对。而在 HyDE 中,我们预先为用户的问题生成多个假设性的回答,再用假设性回答去进行检索而不是使用用户查询。这个想法是,在具有查询-文档不对称的 RAG 系统中,假设文档或片段将比用户查询本身具有更大的语义相似性。用到的 prompt 如下:
Please generate a 1000 character chunk of text that hypothetically could be found on Example banks website that can help the customer answer their question.▶使用查询路由
查询路由器是我们见过的更受欢迎的高级 RAG 技术之一。其思想是当 RAG 系统使用多个数据源时,利用 LLM 将搜索查询路由到适当的数据库。这涉及在提示中预定义路由决策选项,并解析 LLM 的路由决策输出,以便在代码中使用。
为了降低成本并提高 RAG 的质量,本文开发了一种 RAG 决策模式,因为并非所有查询都需要 RAG 查找。因此,识别何时 LLM 可以独立回答查询而无需外部知识,可以提高效率。一个不太明显的例子是,当回答用户查询所需的所有信息已经存在于最近的对话历史中。在这种情况下,LLM 只需重复或稍微改述之前所说的内容。例如:”你能把你最后的信息翻译成西班牙语吗?”或”请像我五岁一样解释最后的信息。”这两种查询都不需要新的检索,因为 LLM 可以简单地使用其内置功能回答这些查询。
在实现的过程中,只需要对不同的分支采用不同的 prompt 即可。
检索后优化
检索后优化涵盖了在检索发生之后但在最终响应生成之前所采用的策略或技术。此时一个关键的考虑因素是:即使已经部署了所有的检索前和检索策略,也不能保证检索到的文档包含 LLM 回答查询所需的所有相关信息。这是因为检索到的文档可能是以下任意或所有类别的混合物:
-
Relevant documents -
Related but irrelevant documents -
irrelevant and unrelated documents -
Counterfactual documents(即与正确相关文档相矛盾的文档)
检索后优化策略包含以下几个方面:
-
使用重排模型 -
prompt compression -
Corrective RAG
▶使用重排模型
Cuconasu 等人的研究《The Power of Noise: Redefining Retrieval for RAG Systems[1]》表明:related but irrelevant documents are the most harmful to RAG systems。他们发现“在某些情况下,准确率下降超过-67%。更重要的是,仅添加一个相关文档就会导致准确率急剧下降,峰值达到-25%。
更令人惊讶的是,同一研究人员发现不相关的文档“如果放置得当,实际上有助于提高这些系统的准确性。”那些构建 RAG 系统的人应该关注这类研究,但也应对自己的系统进行彻底的 A/B 测试,以确认研究结果是否适用于他们的系统。Cuconasu 的研究还表明,将最相关的文档放置在提示中最接近查询的位置可以提高 RAG 的性能。针对这个现象,重排序模型优化了给定查询的块搜索结果的优先级。这种技术在与混合检索系统和查询扩展结合使用时效果很好。相对于向量召回,重排模型的性能略差,但是更能挖掘出 query 和召回文档之间的相关性。
▶prompt compression
LLMs 可以处理每个块中的信息,以过滤、重新格式化甚至压缩最终进入生成提示的信息。LLMLingua[2] 是这种方法的一个有前途的框架。LLMLingua 使用一个小型语言模型,如 GPT2-small 或 LLaMA-7B,来检测并移除提示中不重要的 tokens。它还使得在黑箱 LLMs 中使用压缩提示进行推理成为可能,实现了高达 20 倍的压缩率,同时性能损失最小。LongLLMLingua[3] 更进一步,通过在进行压缩时考虑输入查询,移除一般不重要和对查询不重要的 tokens。值得注意的是,除了完全理解和使用压缩提示来回答查询(例如,作为 RAG 的一部分),即使提示对人类不可读,GPT-4 也可以用于逆向或解压输入。
▶Corrective Rag
Corrective RAG[4] 是一种由 Yan 等人首次提出的方法,其中 T5-Large 模型被训练用于在将结果提供给大型语言模型(LLM)以生成最终响应之前,识别 RAG 结果是否正确/相关、模棱两可或不正确。未通过正确/相关或模棱两可分类阈值的 RAG 结果将被丢弃。与使用经过微调的 Llama-2 7B 模型和 Self-RAG 的批判方法相比,使用 T5-Large 模型要轻量得多,并且可以与任何大型语言模型结合使用。
生成优化
生成优化包括改进生成最终用户响应的大型语言模型调用。这里最容易实现的成果是迭代提示并确定插入到生成提示中的最佳分块数量。我们使用 GPT-4 对 1000、3500 和 7000 个 token 的检索上下文 / 分块进行了 A/B 测试。我们发现,将 3500 个 token 的检索上下文插入到检索增强生成(RAG)提示中比其他选项略好。我们怀疑这个发现并非普遍适用,每个用例都有不同的最佳数量。在这一点上,可以考虑评估和改进大型语言模型适当处理它可能接收的不同类型文档(相关的、有关联的、不相关的等)的能力。理想情况下,一个 retrieval-robust 的 LLM 系统应当具备以下特性:
-
当检索到的上下文相关时,应提高模型性能。 -
当检索到的上下文不相关甚至与事实相反时,不应损害模型性能。 -
未知稳健性:当 LLM 收到一个它没有相应知识来回答的查询,并且在检索到的文档中未找到相关信息时,以‘未知’回应来承认其局限性的能力。
▶思维链
思维链(Chain-of-thought, CoT)提示通过推理增加了在存在噪声或无关上下文的情况下,LLM 得出正确响应的可能性。研究人员 Wenhao Yu 等人进一步发展了这一理念,提出了链式笔记(chain-of-noting[5]),他们微调了一个模型以生成“每个检索到的文档的连续阅读笔记。这一过程允许对文档与所提问题的相关性进行深入评估,并有助于综合这些信息以构建最终答案。”微调的模型是 LLaMA-7B,训练数据是使用 ChatGPT 创建的。
▶通过 Self-RAG 使系统具备自我反思能力
Self-RAG 是另一种基于微调的方法,其中语言模型在生成过程中被训练输出特殊的反思标记。反思标记可以是检索标记或批评标记。研究人员 Asai 等人详细描述了他们的方法:
“给定一个输入提示和之前的生成内容,Self-RAG 首先确定是否通过检索到的段落来增强后续生成会有所帮助。如果是,它会输出一个检索标记,按需调用检索模型。随后,Self-RAG 并行处理多个检索到的段落,评估其相关性,然后生成相应的任务输出。接着,它生成批评标记来批评自己的输出,并选择在事实性和整体质量方面最好的一个。”
▶通过微调忽略不相关内容
鉴于 LLM 通常没有明确地为 RAG 进行训练或调优,因此可以对模型进行微调以适应这种用例,合理地说可以提高模型忽略无关上下文的能力。论文《Making Retrieval-Augmented Language Models Robust to Irrelevant Context[6]》通过实验证明,即使是 1,000 个例子也足以训练模型,使其在面对无关上下文时保持鲁棒性,同时在有相关上下文的例子上保持高性能。
此论文还探索了使用自然语言推理(NLI)模型来识别无关的上下文。由于有些情况下无关的 RAG 上下文会对 LLM 的性能产生负面影响。NLI 模型可以用来过滤掉无关的上下文。这种技术的工作原理是,仅在假设(即使用问题和 LLM 生成的答案)被分类为由前提(即检索到的上下文或 RAG 结果)所蕴涵时,才使用检索到的上下文。
其他 Advanced RAG 策略
关于 RAG 的文献非常广泛且不断扩展。
-
微调 embedding 模型 -
使用知识图谱(即 GraphRAG[7]) -
使用长上下文 LLM(例如 Gemini 1.5 或 GPT-4 128k)代替分块和检索
总结
随着检索增强生成(RAG)系统的快速发展,它为增强对话式 AI 和其他生成式 AI 应用提供了许多机会。本文的实验和研究突显了先进的 RAG 技术在以下方面的潜力:
-
信息密度 -
检索准确性 -
用户响应质量
如果正确实施,这些技术可以为企业带来更高的成本效益,并改善客户体验。但为了跟上快速涌现的最佳实践,软件工程师和数据科学家需要及时、可信赖的资源作为参考。
参考资料
[2]LLMLingua: https://www.microsoft.com/en-us/research/blog/llmlingua-innovating-llm-efficiency-with-prompt-compression/
[3]LongLLMLingua: https://arxiv.org/abs/2310.06839
[4]Corrective RAG: https://arxiv.org/abs/2401.15884
[5]chain-of-noting: https://arxiv.org/abs/2311.09210
[6]Making Retrieval-Augmented Language Models Robust to Irrelevant Context: https://arxiv.org/abs/2310.01558
[7]GraphRAG: https://github.com/microsoft/graphrag
来源:差分隐私